
HtmlUnit爬虫获取页面信息
HtmlUnit是一个没有GUI的模拟浏览器测试框架,之前在Python使用过Slenium进行自动化测试和一些爬虫的操作。但是Slenium在使用的时候会出现一个浏览器界面进行真实操作。
HtmlUnit可能在编排代码的时候不知道浏览器现在是什么情况,可能会有很难写下去的情况。
-
POM中引入HtmlUnit
<!-- https://mvnrepository.com/artifact/net.sourceforge.htmlunit/htmlunit -->
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.70.0</version>
</dependency> -
编写代码
package org.example;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.apache.http.HttpHost;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.client.utils.URIUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.IOException;
import java.net.URI;
import java.util.List;
public class JsoupHttpClient {
public static void main(String[] args) throws Exception {
WebClient webClient = getWebClient();
// 短链接变成长链接
String url = getAbsUrl("https://nnfp.jss.com.cn/scan-invoice/printQrcode?paramList=xxxxx&aliView=true");
HtmlPage page = webClient.getPage(url);
// 有的时候需要等待一会js的代码执行
// webClient.waitForBackgroundJavaScriptStartingBefore(30000);
// 定位到页面下载PDF的按钮
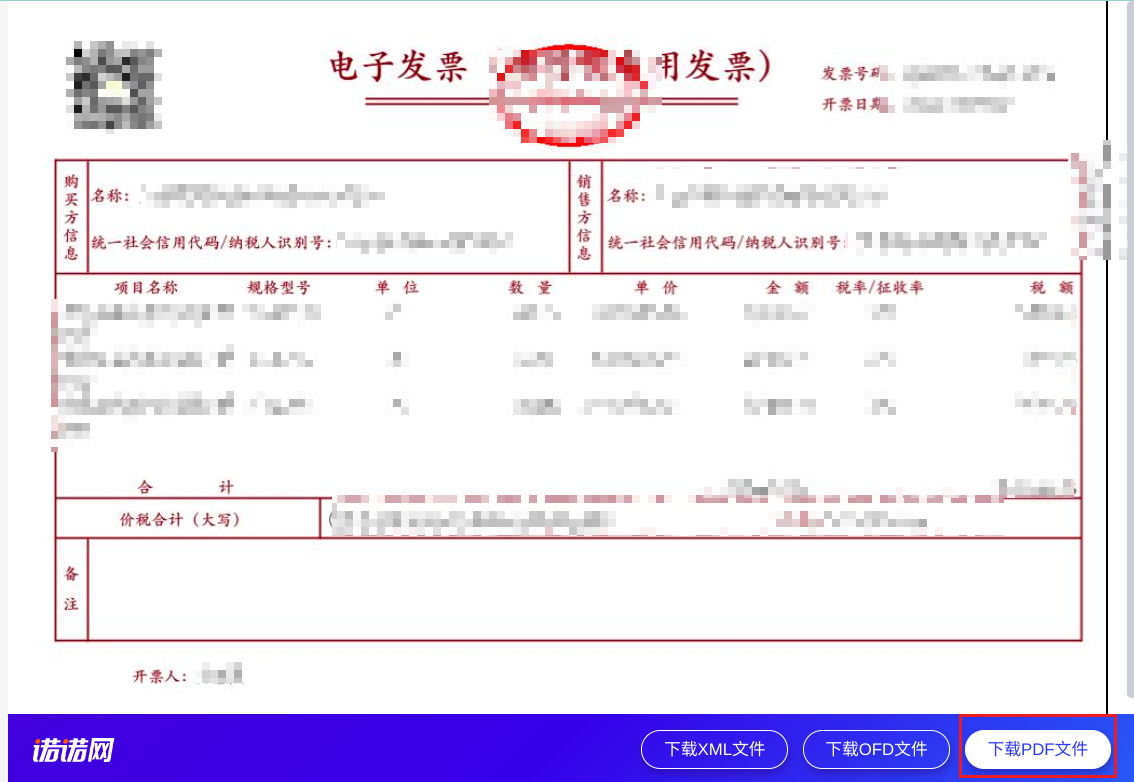
List<HtmlElement> spanList = page.getByXPath("//div[@class='logo-btn-area']/a[@class='primary']");
HtmlElement htmlElement = spanList.get(0);
String string = htmlElement.click().getUrl().toString();
System.out.println(string);
}
private static WebClient getWebClient() {
WebClient webClient = new WebClient(BrowserVersion.EDGE);
// webClient.getOptions().setCssEnabled(true);//(启用)css 正常来说css不会影响到爬虫数据抓取,但是诺诺发票关闭css就会出现问题
// webClient.getOptions().setThrowExceptionOnScriptError(false);//(屏蔽)异常
// webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//(屏蔽)日志
// webClient.getOptions().setJavaScriptEnabled(true);//加载js脚本
// webClient.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
// webClient.getOptions().setTimeout(50000);//设置超时时间
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//设置ajax
return webClient;
}
/**
* 处理跳转链接,获取重定向地址
*
* @param url 源地址
* @return 目标网页的绝对地址
*/
public static String getAbsUrl(String url) {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpClientContext context = HttpClientContext.create();
HttpGet httpget = new HttpGet(url);
CloseableHttpResponse response = null;
String absUrl = null;
try {
response = httpclient.execute(httpget, context);
HttpHost target = context.getTargetHost();
List<URI> redirectLocations = context.getRedirectLocations();
// System.out.println("httpget.getURI():" + httpget.getURI());
URI location = URIUtils.resolve(httpget.getURI(), target, redirectLocations);
// System.out.println("Final HTTP location: " +
// location.toASCIIString());
absUrl = location.toASCIIString();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
httpclient.close();
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return absUrl;
}
}
代码中先使用了getAbsUrl方法,把对应的短链接变成长链接,然后获取浏览器连接,通过XPATH定位的方法//div[@class='logo-btn-area']/a[@class='primary']定位到页面下载PDF的按钮,然后点击下载

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 喵喵博客!





